In diesem Blogpost wird die in DaPro entwickelte Methodik zur vereinfachten Wiederverwendung von Datenanalysen beschrieben. Die entwickelte Methodik zielt darauf ab Analysen, die ein Mal durchgeführt wurden, mit geringerem Konfigurationsaufwand auf ähnliche Kontexte anpassen zu können.
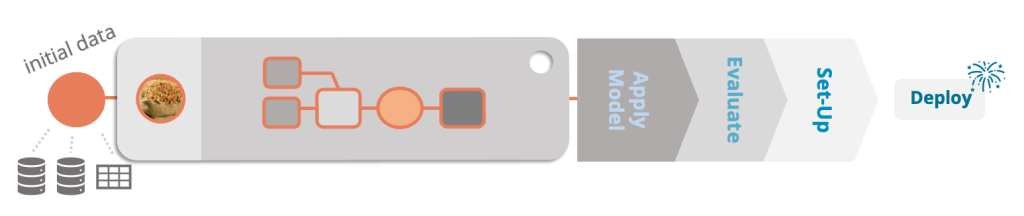
Kern der Methode sind sogenannte Problemlösungsmodule. Ein Problemlösungsmodul umfasst dabei Daten- und Analysemodule, die über den Problemkontext angepasst und verknüpft werden, um einen Datenanalyse-Use-Case umzusetzen.

Ziel ist es bei einer initialen Bearbeitung einer Analyse versch. Analysemodule zu kombinieren bzw. neu zu erstellen und mit Datenanforderungen zu verknüpfen. Anschließend werden die Einstellungsmöglichkeiten der Umsetzung im Expert:innenaustausch auf relevante Charakteristika reduziert.

Die so entstandenen Problemlösungsmodule können dann für andere Abteilungen oder auch Unternehmen bereitgestellt werden. Diese können anhand der Datenanforderungen sehen, welche Daten ihrerseits bereitgestellt werden müssen.

Anschließend werden automatische Datenanpassungen durchgeführt und Anwendende müssen lediglich die zuvor definierten relevanten Charakteristika konfigurieren. Diese fokussieren sich auf den jeweiligen Kontext z.B. das Brauwesen und erfordern kein Wissen über Analysemethoden.

Entwickelte Problem-Lösungsmodule können dann beispielsweise über einen Katalog bereitgestellt werden. Dieser beinhaltet dann Problembeschreibungen und Beschreibung der Eigenschaften benötigter Daten zur Lösung. Neuer Anwender:innen können somit mit einem Katalog an fertigen Lösungen starten, und sich potentielle Analysen heraussuchen und anpassen.